
특징 추출을 완료했다면, 어느 특징이 가장 모델링에 적합한지 판단해야 한다.
실습자료 코드는 텐서플로우 1.x 기반으로 작성되어 있는데, 현재 m1 mac에서는 최소 2.x부터 지원하므로 현재 실습환경은 2.13 버전으로 구성되어 있다.
문제는 1.x 버전에서 2.x 버전으로 넘어가면서 많은 부분이 변경되어서 1.x 버전의 코드로는 온전히 실행이 불가능했다.아래는 분석은 잠시 미뤄두고 코드를 실행시키기 위한 눈물겨운 노력의 과정이 담겨 있다.
첫 번째 코드
필요한 라이브러리를 임포트 하고 csv파일을 불러오는 코드이다.
파이썬 3을 사용 중이라면 print구문에 괄호를 달아주어야 한다.

첫 번째 코드의 오류
실행해 보니 다음과 같은 오류가 발생했다 seaborn 라이브러리가 설치되어있지 않다고 한다.
필요 패키지를 설치한다.

pip install seaborn
model.py 파일에 문제가 있다고 한다.
model.py 파일이 최신 문법에 따르지 않아 생기는 문제이다. 다음과 같이 수정해 주었다.

model.py에 import tensorflow as tf대신 아래 코드를 입력
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
이번엔 cnn_model.py 에서 오류가 났다고 한다.
텐서플로 최신버전에서 utils 모듈이 삭제되고 categoirical로 변경되었다
from keras.utils import np_utils를 from tensorflow.keras.utils import to_categorical 변경해주어야한다.

그리고 해당 코드는 텐서플로 1.x 버전에 맞게 작성된 코드이나 현재 환경은 2.x 버전이므로
코드가 동작할 수 있도록 import구문을 수정해 준다.
1,2라인을 아래와 같이 수정한다.
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior() # TF 2.x에서 1.x 동작 강제
최종 수정결과 (cnn_model.py)

결과가 제대로 나왔다!

아래는 책의 실습환경으로 진행된 결괏값이다 약간의 차이가 있었다.

두 번째 코드
두 번째 코드는 특징에 (csv) 누락된 행을 제거하는 코드이다.
pe_header.py를

print구문을 python 버전에 맞게 수정한다.
코드를 실행해 보면 누락된 값은 총 750개가 되며 삭제 후 데이터의 개수는 63개가 줄어든 것을 확인할 수 있다. (한 행에 여러 개의 누락된 값이 있을 수 있으므로)

세 번째 코드
세 번째 코드는 pe 헤더 특징 중 범주형 데이터를 삭제하는 과정이다.
범주형 데이터란 수치로 표현할 수 없는 데이터를 말하며, 예를들어 [사과, 배, 감, 수박]이나사과,배,감,수박] 이나 [빨강, 파랑, 검정]빨강,파랑,검정] 등 순서를 가지지 않는 데이터를 말한다.
대부분의 학습 알고리즘은 범주형 데이터를 처리하지 못하고 수치형 데이터만 사용할 수 있으므로 이 데이터들을 삭제해주어야 한다.
속성 중 [filename, MD5, packer_type] 열을 삭제해 준다.
세 번째 코드의 오류
3번째 코드에서 다음과 같은 오류가 발생했다.

열을 명시해줘야 한다길래 그에 맞게 수정했다. 아래와 같이 각각 수정해 주자
pe_all = pe_all.drop(['filename', 'MD5'], 1) # 파일이름, MD5 열 제거
pe_all = pe_all.drop(['filename', 'MD5', 'packer_type'], axis=1)X = pe_all.drop('class',1)
X = pe_all.drop('class', axis=1) # 카테고리 열 제거그런데 이번엔 이런 오류가 발생했다.
코드를 수정했으면 처음부터 코드를 다시 실행해 주어야 한다.

실행결과

열이 정말 삭제되었는지 확인한다.
삽입할 위치에 커서를 두고 + 버튼을 클릭
pe_all.head() 코드를 입력하고 재생 버튼으로 코드를 실행한다.
packer 옆에 packer_type 열이 있었는데 사라진 것을 확인할 수 있다.

4번째 코드
코드를 아래와 같이 수정

5번째 코드

실행해 보니

sparse 매개변수가 버전 1.2에서 sparse_output으로 이름이 변경되었으며, 버전 1.4에서 sparse 매개변수가 제거될 것이라는 알림이다. 아직은 사용할 수 있다.
경고를 없애려면 네 번째 코드를 아래와 같이 수정한다.

6번째 코드
axis =1로 수정한다

8번째 코드

cnn_model.py 파일을 열어 다음과 같이 수정

이번엔 또 다른 오류가 발생했다.

아래와 같이 수정

또 오류가 생겼다.

해결 과정
계속해서 오류가 반복되어 텐서플로우 1,2 버전에버전에 대해 찾아보았다.
텐서플로우는 2로 넘어오면서로넘어오면서 코드의 많은 부분이 변해서 아예 코드를 새로 짜거나,
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
compat 모듈을 사용하면 1의 코드들을 대부분 그대로 사용가능하다.
그런데 contrib 모듈의 경우 위 방법으로도 사용이 불가하다.
그래서 코드를 다시 원래대로 돌리고, contrib 부분만 바꿔보기로 했다.
아랫부분이다.
아랫부분을 강제한 텐서플로우 1.x에 맞게 짜되, contrib는 사용하지 않아야 한다.
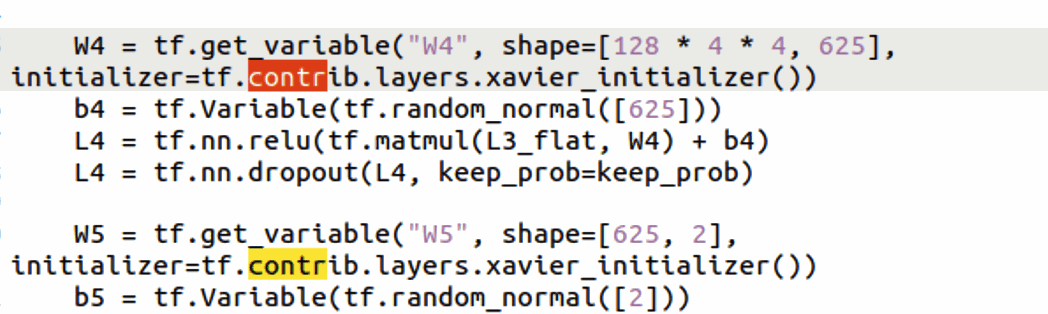
그러다 계속 오류가 반복되어 결국 코드를 전체적으로 tesorflow2.x 에 맞게 마이그레이션 하기로 결정했다.
실습자료로 제공된 원본 cnn_model.py를 마이 그레 시원하다. (model.py도 함께 마이그레이션 해보았으나 오류가 계속 생겼고, compat.v1을 사용해도 잘 실행되었다.)
아래명령어를 사용하면 손쉽게 바꿀 수 있다.
tf_upgrade_v2 --infile 바꿀파일이름. py --outfile 저장할파일이름.py
그런데 실행하니 아래와 같이 오류가 났다. report.txt를 확인해 보니 스페이스와 탭을 혼용해서 발생하는 문제라고 한다.

코드를 수정하고 다시 실행해본다.

이 파일들을 실습폴더에 옮기고 기존의 코드는 backup 해 둔다.

이제 주피터를 재 실행 해본다.
같은 오류가 발생했는데, 찾아보니 tf_upgrade_v2는 import는 바꾸지 않는다고 한다.
다시 import를 수정한다.
from tensorflow.keras.utils import to_categorical
#from keras.utils import np_utils
마이그레이션 작업으로 변경되지 않았던 코드를 다시 수정한다.
Y_train = to_categorical(y_train, nb_classes)
Y_test = to_categorical(y_test, nb_classes)
커널을 재시작한 뒤 코드를 실행.
실행이 되었으나.. 0.0000000 결과가 모두 0으로 나왔다.

코드를 다시 확인해 보니 이미지 파일들의 경로가 맞지 않아 에러가 났다.

코드를 수정해 주었다.

다시 커널을 재시작한 뒤 실행
드디어 제대로 결과가 나왔다!!
아래 systemmemory 내용은 현재 사용 중인 시스템에서 사용할 수 있는 램 용량이 부족하다는 알림이다.
프로세스를 확인해 필요 없는 프로세스를 종료해 주자.

너무 길어진 관계로 Featrue Engineering(특징 공학)부터는 다음 포스트에 서술한다.